[CH] ClickHouse Getting Started
[TOC]
ClickHouse Client CLI
# 等價於文件中的 "./clickhouse client" 或 "clickhouse-client"
$ clickhouse client --help
$ clickhouse client -m # --multiline,在 CLI 中使用 ; 當作結尾
$ clickhouse client -q [query] # --query,在啟動 client 時,直接執行 query
$ clickhouse client -m --config-file="custom-config.xml"
在 ClickHouse Client 中下 Query 的方式:
- 如果希望換行輸入 Query,需要在換行前使用
\ - 如果有使用
multiline模式,則可以隨意換行,直到使用;後,程式才會執行 - 直接在啟動 CLI 時輸入 Query 可以使用
-q [query],例如clickhouse client -q "SHOW DATABASES"。
# 進入 clickhouse client 後
USE "example-db"; # 切換到某一 database
SELECT * FROM db.table FORMAT VERTICAL;
ClickHouse Architecture
MergeTree Table Engine
在 ClickHouse 中,不同的 Table Engine 會影響到:
- 資料保存的方式與位置
- 能夠使用那些方式 queries
- 資料如何被複製(replicated)
- 能不能並行存取資料
- 是否資源 multithreaded requests
當你想要把資料放到 ClickHouse 中處理時,就會使用 MergeTree Table Engine,它適合用在 high-load tasks。MergeTree Table 系列的 Engine 設計來以快速插入資料並隨後在背景資料處理。它們專為高資料擷取率和巨量資料而設計。
TL;DR
granule:和資料讀取有關,是 ClickHouse 在讀取資料時的最小單位,預設是 8,192 筆資料primary key:資料表排序的方式,它應該要是搜尋資料時,WHERE最常被用到的欄位primary index:保存在記憶體中的索引,它會是每個 granule 中的第一筆資料part:和資料寫入有關,ClickHouse 在每次 INSERT 資料時,就會建立一個新的資料夾,這個資料夾就稱作 part,裡面包含 column files 和 index file
Primary Key
keywords: granule
Primary Key 決定了:
- 資料如何被保存在硬碟上,會影響到資料儲存所佔用的容量
- Primary Index 中會有哪些值,會影響到能不能有效率的查詢資料
Best Practice
-
主鍵:
- 並不保證是唯一(unique)的
- 主鍵可以通過
PRIMARY KEY參數來設置,它同時也會是 sorting keys。- 預設如果不設置 PRIMARY KEY,則
ORDER BY中的欄位將自動成為 primary keys。 - 當同時設置
PRIMARY KEY和ORDER BY時,primary keys 必須是 sorting keys(ORDER BY)的子集合,也就是 primary keys 一定要包含在 sorting keys 中
- 預設如果不設置 PRIMARY KEY,則
- 資料在保存時會根據 PRIMARY KEY 進行排序,因此 PRIMARY KEY 的設定會影響到資料能不能被有效的壓縮,進而影響到最終資料所使用到的硬碟容量
-
Primary Key 的選擇
- 在搜尋資料時,在
WHERE中最常被使用到的欄位,就應該要把這個欄位設成 Primary Key。 - 只有這個欄位能幫助你跳過許多 granules 時,才把它加到 PK 中。添加過多無意義的 PK 只會增加記憶體的負擔,不會帶來實際的效益。
- 盡量選擇資料變異性小的資料作為 Primary Key 通常能提供越大的效果。把 String 的欄位放在 Primary Key 就會是一個很不好的使用。
- 在搜尋資料時,在
-
Primary Key 擺放的順序
- 除了把最常會用到的欄位放在第一個 PK 之外,一般可以把基數(資料變異性)越低的欄位放在越前面越好,如此有機會在搜尋時,可以略過越多查詢不必要的資料。
-
當你要在一個 Table 建立多個 Primary Keys 時,請先考慮以下的做法:
- 建立兩個帶有相同資料的 Table,這兩個 Table 的差別只有在 Primary Key 不同
- 使用 Materialized View,透過
SELECT把資料保存在另一個 Table 中,並在SELECT中來排序該資料
- 使用 Materialized View,透過
- 使用 Projection
- ClickHouse 在背後建立一個隱藏的資料表,這個資料表會用不同的方式來排序
- 定義 Skipping Index
- 建立兩個帶有相同資料的 Table,這兩個 Table 的差別只有在 Primary Key 不同
Primary Keys 欄位的資料會被保存在記憶體中,一旦新增資料,這些保存在記憶體中索引就會需要重新建立。因此過的不必要的 Primary Keys 對於效能會有不好的影響。
CREATE TABLE helloworld.my_first_table
(
user_id UInt32,
message String,
timestamp DateTime,
metric Float32
)
ENGINE = MergeTree()
PRIMARY KEY (user_id, timestamp); # 設定的 Primary Keys 預設也會是 Sorting Keys
Granule
在 ClickHouse 中:
-
Primary Key 決定了資料會如何被保存和被搜尋
- ClickHouse 會在「每 8,192 個 rows」或「10 MB 的資料」在主鍵索引檔案中建立一個條目(
entry),這樣的顆粒度(granules)會是在以SELECT進行查詢時的最小資料塊(column data)。 - 由於資料保存的時候會先以 Primary Key 排序,所以在進行查詢時,ClickHouse 不需要逐行掃描資料,而是先看這個「條目」,從這些條目中找出符合的資料塊,再從資料塊中找出符合條件的資料,從而提升查詢效率。
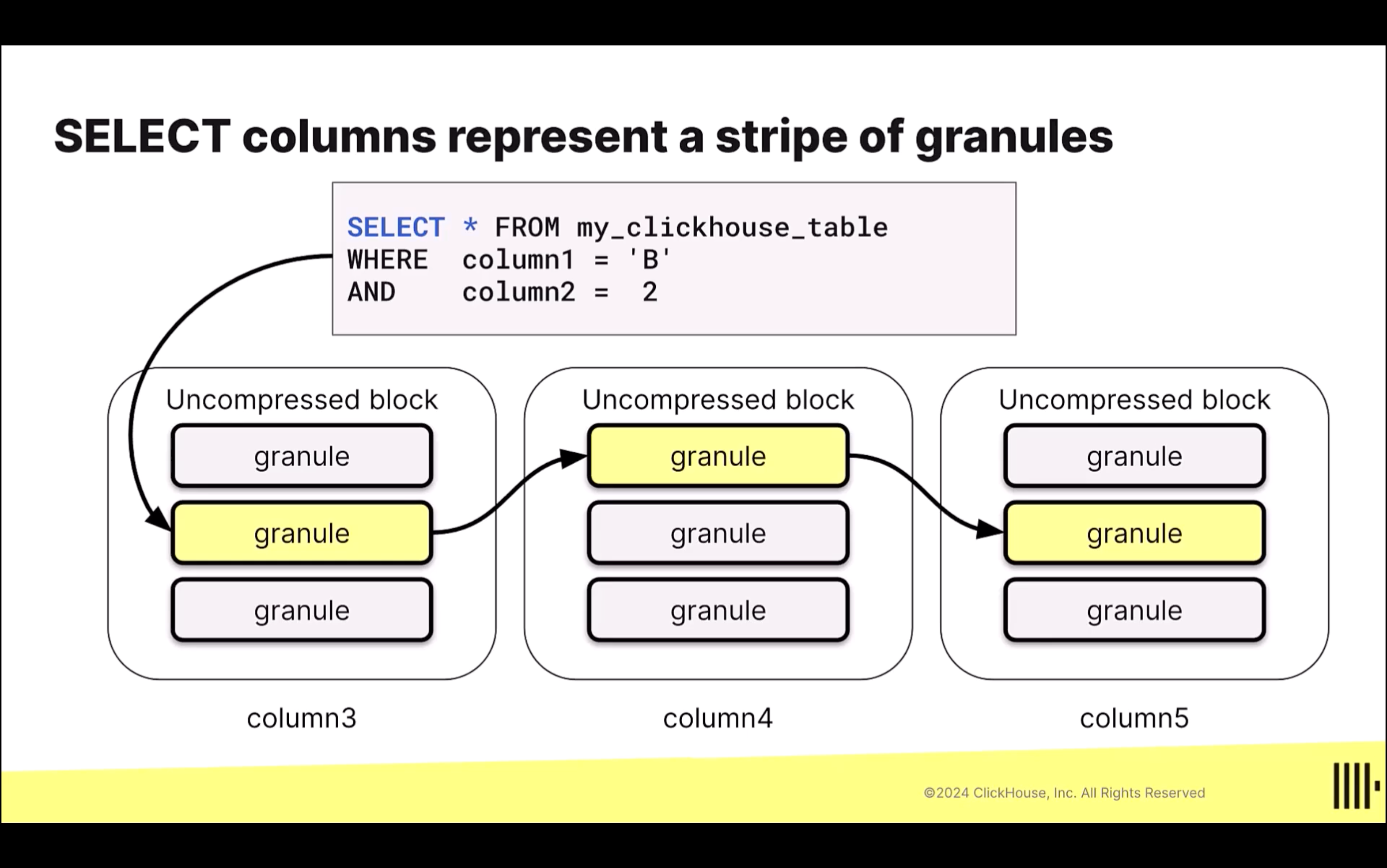
- 以下圖為例,在第 1、8,193、16,385、24,577 筆資料,都會被紀錄成條目。如果要找出
Column 1 = A、Column 2 = 2的資料,只需要先掃描這個條目,在開始掃描這兩個條目中的資料塊。
- ClickHouse 會在「每 8,192 個 rows」或「10 MB 的資料」在主鍵索引檔案中建立一個條目(
不把每一個 row 都建立 index,而是每 8,192 筆資料才建立一個 entry 的方式稱作 Sparse Index,透過這種方式,即使有上百萬筆資料,也只需要建立幾百個索引即可。一個 granule(資料塊)中的第一筆資料就會時 Primary Index,它有稱作「Entry」或「Mark」。Entries 會被存在 Memory 中,所以可以和快速存取,同時它會保存在 part folder 中的 primary.cidx 中作為備份。

granule 時 ClickHouse 在讀取(搜尋)資料時的最小單位,也就是說,如果你只是要找一筆資料,ClickHouse 至少也會需要從 8,192 筆資料中去找到它。
granule 是資料搜尋時用的方式,和資料的保存沒有直接關係。
ClickHouse 在搜尋資料時,會用 Stripe of Granules 的概念:
- 每一個 Stripe of Granules(8,192 筆資料)都會被丟到一個 thread 去處理
- Stripe 彼此之間時 concurrently 的被處理(這就是為什麼 ClickHouse 可以這麼快!)
- Faster threads 可以從 slower threads 偷 tasks 來做
Partition
在 ClickHouse 中,Partition 的主要用途是管理資料(data management),並不會使用 Partition 來略過某些資料以優化查詢(這是要用 Primary Key 來達到)。
使用 Partition 的唯一建議是:以「月」來分割資料,例如,PARTITION BY toYYYYMM(created_at)。除非你真的每天都會有大量的資料進來,這時候再來考慮以「日」來分割資料。
- 大部分的情況下,你並不需要使用 Partition Key,而是應該聰明選擇你的 Primary Key。
亂用 Partition 會使得在 ClickHouse 中有過多的 Parts:
- 只有在同一個 Partition 中的 Parts 會被合併
- 不要使用
user_id、地理位置、電子信箱等欄位作為 Partition Key
除非資料量真的非常大,否則使用 partition 只會讓 part 變成非常多。
邏輯上,設定 Partition 的確能達到優化資料查詢的結果,但這並不是使用 Partition 的理由。不要試著用 Partition 來嘗試略過 granules,而應該是要用 PRIMARY KEY。
CREATE TABLE partition_demo
(
`user_id` UInt32,
`message` String,
`timestamp` DateTime,
`metric` Decimal(30, 2)
)
ENGINE = MergeTree
# highlight-next-line
PARTITION BY toYYYYMM(timestamp)
PRIMARY KEY user_id;
Insert
keywords: part
Best Practice
# https://clickhouse.com/docs/en/guides/inserting-data
INSERT INTO helloworld.my_first_table (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0 ),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421 ),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718 ),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159 );
- 建議一次插入多筆資料,減少執行 INSERT 的次數
- 最好每次的 INSERT 都能至少有 1000 筆資料;最理想的話,是一次 10,000 到 100,000 筆資料
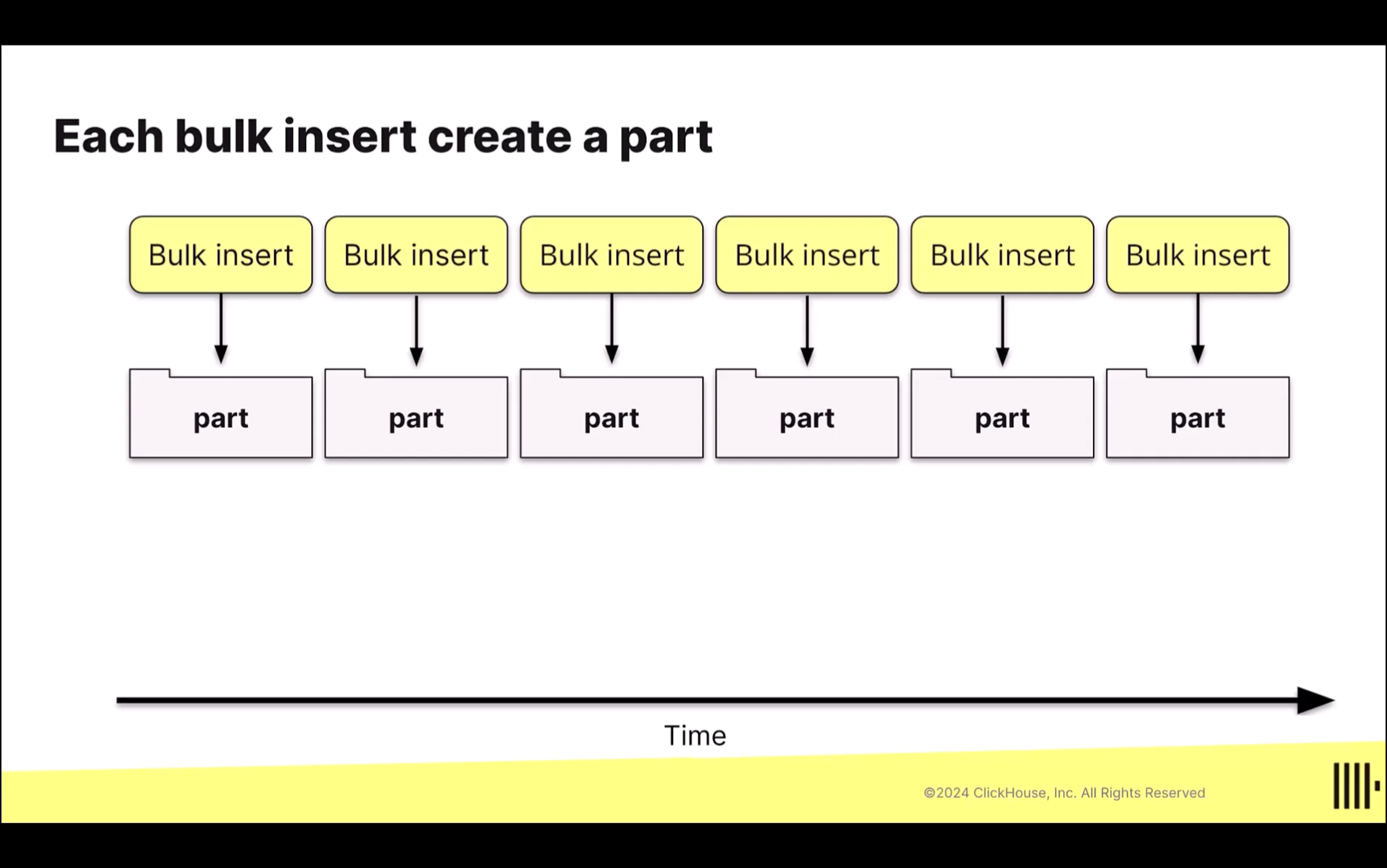
- 每次 bulk INSERT 時,這些資料都會被放在同一個資料夾中,這個資料夾有一個特殊的名稱,稱作 part;也就是說,每次 bulk INSERT 時,都會建立一個 part,這個 part 中可能包含數萬,甚至數百萬筆資料;每個 part 會被保存在它��自己的資料夾中。
- 建議確保 batch insert 時資料的順序
- 當資料 INSERT 失敗時,只要當初插入的資料保有一樣的內容和順序,ClickHouse 會自動 deduplicate 這個插入(仍取決於所選的 ENGINE)。
- 因此,即使因為網路問題或節點問題而導致錯誤發生時,只要確保資料內容和順序相同,重複多次執行 INSERT 並不會有問題
- 如果一次能 INSERT 的資料筆數較少,建議使用 asynchronous inserts
- 如果 client 端沒辦法批次插入多筆資料,則應該考量使用 asynchronous insert,這可以將 batching insert 的責任委派給 ClickHouse。
- 透過 asynchronous inserts,資料會先被建立在記憶體的緩衝區,只有在緩衝區的資料被刷新後(flush),資料才會被保存進資料庫,否則,在刷新前,是沒有辦法在資料庫中查詢到這個資料的。
- 這個刷新頻率和 asynchronous inserts 是可以設定的

Part
在 ClickHouse 中,每次 INSERT 都會建立一個��資料夾(part),也就是說,如果不使用 bulk INSERT 或 async INSERT,而是一筆一筆新增資料的話,就會建立出超多個資料夾(part)。
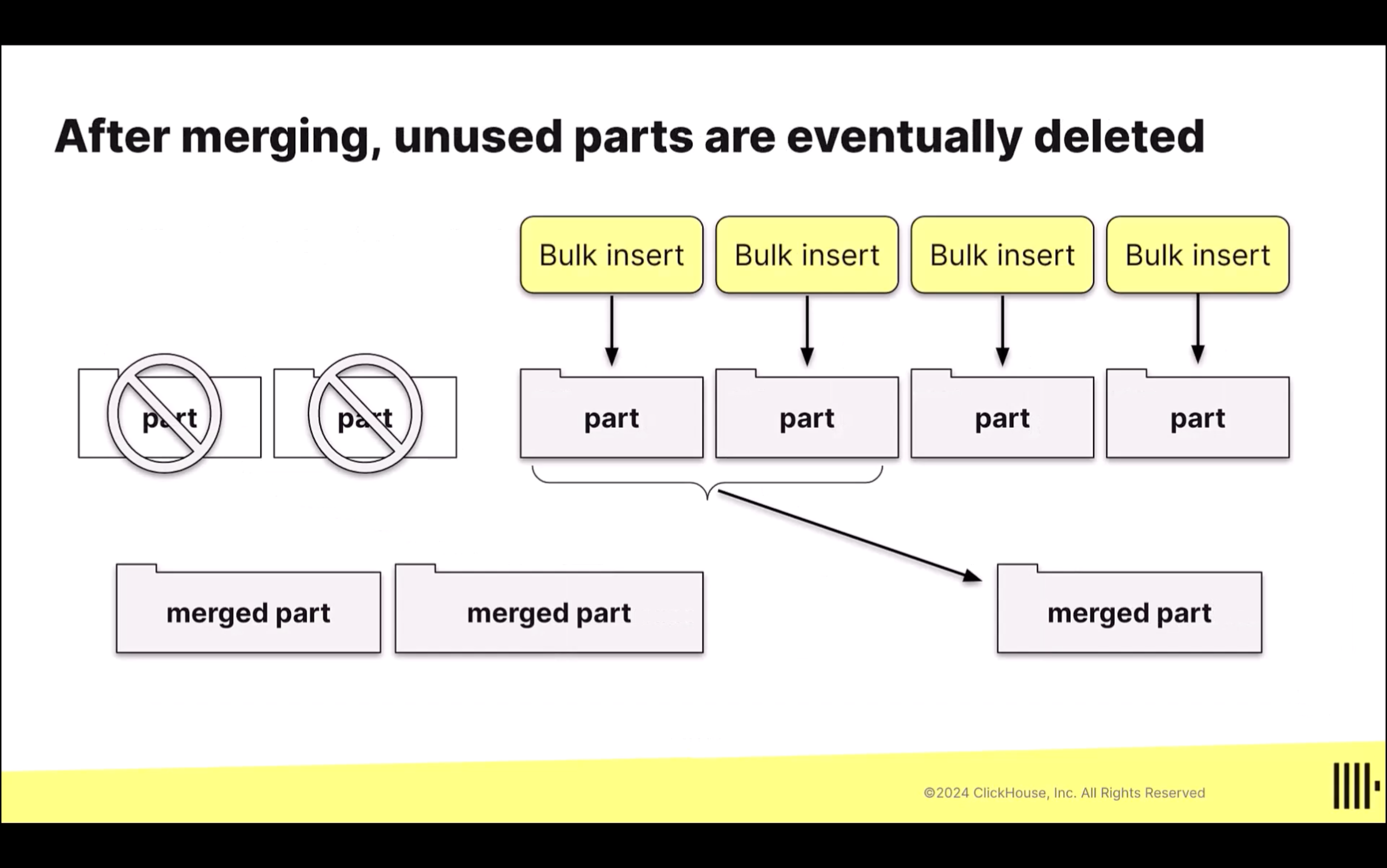
- 多個 Part 會在 ClickHouse 背景中被合併成一個新的 merged part,然後多個 merge 過的 part 又會在繼續合併成新的 merged part,就這樣持續合併,直到超過特定的檔案大小(
max_bytes_to_merge_at_max_space_in_pool)後才停止。這也就是為什麼這個 Engine 被稱作 MergeTree。

SELECT Queries
ClickHouse 支援多種不多的輸入與輸出的資料型態。例如,在輸出時,可以使用 FORMAT 指令來以多種不同的格式來呈現資料:
SELECT *
FROM helloworld.my_first_table
ORDER BY timestamp
FORMAT VERTICAL;
Modeling Data
- Schema Design @ Data Modeling
在 ClickHouse 中,database 其實只是一個 namespace,一種分類 table 的方式。也就是說,如果 1 個 database 裡有 100 張表,和有 100 個 database,�每個 database 中都只有一張表,這兩種方式消耗的資源基本上是一樣的。
CREATE DATABASE my_database;
CREATE TABLE my_table
(
user_id UInt32,
message String,
timestamp DateTime,
metric Decimal(9, 4)
)
ENGINE = MergeTree
PRIMARY KEY (user_id, timestamp);
��檢視某個 Field 的 DataType
keywords: toTypeName
SELECT columnName, toTypeName(columnName) AS columnType
FROM yourTable
LIMIT 1;
檢視支援的 DataType 和 Alias
Data Types @ ClickHouse
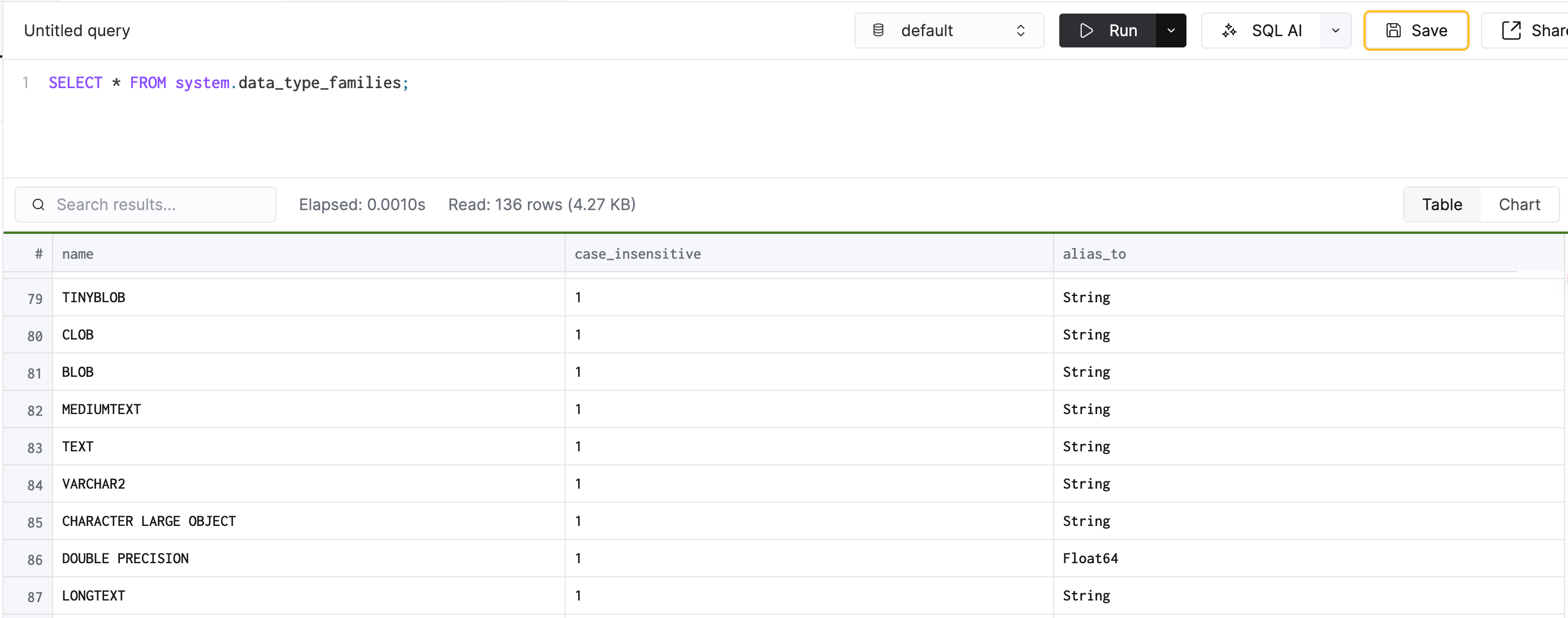
# 檢視 ClickHouse 中所有支援的 datatype 和其 alias
SELECT * FROM system.data_type_families;
# 找出所有其實是 String 的 alias data type
# 例如,不論你用 VARCHAR、TEXT 或 BLOB,實際上它們在 ClickHouse 中的 DataType 都是 "String"
SELECT * FROM system.data_type_families WHERE alias_to = 'String';
String
String:可以是變動長度的字串FixedString(N):固定長度的字串- 當插入的字串長度超過
N時,ClickHouse 不會 trim 掉多餘的長度,而是會噴錯 - 當插入的字串長度小於
N時,ClickHouse 會用nullbytes 來填補不足的長度
- 當插入的字串長度超過
Date / Datetime
- 儲存資料時可以使用字串或數值,例如
INSERT INTO
date_datetime_example
VALUES
(
'1970-01-01',
4102444800,
'2105-01-01 12:05:05',
'2299-01-01 12:05:05.123456',
now(),
now() - INTERVAL 1 WEEK
);
Date:可以從 1970-01-01 用到 2149-06-06,只精確到秒Date32:如果需要使用 1970 �以前的時間DateTime('Asia/Taipei'):可以保存時區資訊,但只精確到秒DateTime64(precision, 'Asia/Taipei'):precision 指的是要精確到秒、毫秒、或微秒
Array
- Array 中的元素型別必須要是相同的(
null除外),否則會噴錯 - Array 最多可以保存 1 百萬(1 million)個元素
- 在 ClickHouse 中,Array 中第一個元素的 index 是
1(不是0)!
# 建立一個 meetings 是 Array(DateTime) 的欄位
CREATE TABLE array_example (names Array(String)) ENGINE = MergeTree PRIMARY KEY names;
# 要把資料作為 array 塞進 database 時,可以使用 array() 或 []
INSERT INTO
array_example
VALUES
([ 1, 2, 3 ]),
(array(4, 5, 6));
# 讀取資料
SELECT * FROM array_example;
# 只讀取 Array 中的第一個元素
SELECT names[1] FROM array_example; # 1, 4
Nullable
對於 Non-Nullable 的欄位來說,如果 INSERT 時沒有填入資料,或填入 Null 時,該欄位會是 default value,例如 0 或空字串;如果是 Nullable 的欄位,如果填入 Null 則該欄位會是空的。
CREATE TABLE demo_nullable
(
`name` String,
`age` UInt32,
`height` Nullable(UInt32)
)
ENGINE = MergeTree
PRIMARY KEY name;
INSERT INTO demo_nullable VALUES
('John', 32, 181),
('Jane', Null, 161),
('Dane', 31, Null),
(Null, 1, 40);
# 新增一筆只有 "name" 的資料
INSERT INTO demo_nullable ("name") VALUES ('Aaron');
如果我們去查詢這個 Table 內容,可以看到:
name和age因為不是Nullable,所以在 INSERT 時如果帶入Null,則它會用 default value 來填入(例如""或0)height因為是Nullable,所以在 INSERT 時如果帶入Null,它可以存入「空值(Null)」。
SELECT * FROM demo_nullable;
# ┌─name──┬─age─┬─height─┐
# 1. │ │ 1 │ 40 │
# 2. │ Dane │ 31 │ ᴺᵁᴸᴸ │
# 3. │ Jane │ 0 │ 161 │
# 4. │ John │ 32 │ 181 │
# 5. │ Aaron │ 0 │ ᴺᵁᴸᴸ │
# └───────┴─────┴────────┘
不要濫用 Nullable
Nullable 的資料在保存時,實際上會多佔用一個隱藏的欄位,因此,如果你的資料不需要保存 Null,那麼就讓它是 default value 即可,如此可以節省資料庫所消耗的容量。
因為 Nullable 欄位會佔用更多的空間,建議只有在從商業邏輯的角度思考後,把資料保存成 Null 有其重要性時,才把該欄位設為 Nullable,否則的話,則不建議使用。
如果保存的資料是 Null,那麼在計算一些數值(例如,平均數)的時候,就不會用到這筆資料。
Enum
- 使用
Enum()可以定義 enumerates - Enum 在使用時看起來像字串,但實際上 ClickHouse 會以整數的方式保存它
要定義 Enum 時,可以考慮使用 LowCardinality,後者可提供更有彈性的操作。
# 建立 Table
CREATE TABLE enum_demo (
device_id UInt32,
# 定義 enum
device_type Enum('server' = 1, 'container' = 2, 'router' = 3)
) ENGINE = MergeTree PRIMARY KEY device_id;
# 新增資料
INSERT INTO enum_demo VALUES (123, 'router');
INSERT INTO enum_demo VALUES (456, 'container');
# 新增不是不符合 enum 的資料是會拋錯,DB::Exception: Unknown element 'pod' for enum
INSERT INTO enum_demo VALUES (789, 'pod');
Low Cardinality
-
適合用在當資料實際值不會有太多不同的可能性時
-
如果資料的可能性不會超過 10000 種,用
LowCardinality這個 data type 可以大幅提��升資料讀取和保存的效能 -
String,FixedString,Date,DateTime, 和 numbers(除了Decimal之外),都可以變成 Low Cardinality
-
-
相較於
Enum,LowCardinality在使用上更有彈性,且一般來說,可以提供相等、或更好的效能LowCardinality和enum一樣,背後都會用整數來保存資料LowCardinality可以動態添加新的值,所以你不必在一開始定義 Table 時,就把所有可能的值都先定義好
當要使用 String 或 Enum 來定義欄位的資料型別前,可以先考慮看看能不能用 LowCardinality。
-
建立 Table
CREATE TABLE low_cardinality_example(`column1` LowCardinality(String))ENGINE = Log -
插入資料:
INSERT INTO low_cardinality_example VALUES('a'), ('b'); -
讀取資料:
SELECT column1 FROM low_cardinality_example;
未整理
-
Numeric
- Integer
- Signed
SELECT toInt16(3214.2);
- Unsigned
- Signed
- Float
SELECT toFloat32(12);
- Decimal
toDecimal32(number, S)S表示 Scale,指要顯示到小數地幾位
SELECT toDecimal32(3.141212, 5);會得到3.14121SELECT toDecimal32(3.14,2) + toDecimal32(2.1412, 4);會得到1.46,ClickHouse 會無條件捨去
- Infinity and NaN
SELECT -1/0, 1/0;會得到-inf和infSELECT 0/0;會得到nan
- Integer
-
Tuple
- Tuple 需要至少包含一個元素
SELECT tuple(1,2,'a',toDate('1999-01-15'));
-
Nested
-
Table 的 cell 裡的資料是另一個 table
-
建立 Table
CREATE TABLE nested_example(`ID` Int16,`Details` Nested(Name String, Age UInt8, Height UInt8))ENGINE = Log -
插入資料:
INSERT INTO nested_example VALUES (1, ['A', 'B'], [31, 25], [174, 168]); -
讀取資料:
SELECT ID, Details.Age, Details.Height FROM nested_example;
-
-
Geo
Common Table Expressions (CTE)
# 建立一個叫做 time 的常數,其值是 'LONDON'
WITH 'LONDON' AS my_town
SELECT avg(price)
FROM uk_price_paid
WHERE town = my_town;
# 建立一個叫做 time 的常數,其值是 now()
WITH now() AS time
SELECT
toTimeZone(time, 'Asia/Taipei'),
toDate(time),
toYYYYMM(time),
time - 1,
time - INTERVAL 1 DAY,
toStartOfMonth(time),
addWeeks(time, 2),
formatDateTime(time, '%Y%m%d')
FORMAT VERTICAL;
# 透過 SELECT 建立出一個新的常數,稱作 overall_max
WITH (
SELECT max(price)
FROM uk_price_paid
) AS overall_max
SELECT
town,
max(price) / overall_max
FROM uk_price_paid
GROUP BY town
ORDER BY 2 DESC
LIMIT 2
# 建立出一個 subquery,稱作 most_expensive
WITH most_expensive AS (
SELECT * FROM uk_price_paid
ORDER BY price DESC
LIMIT 10
)
SELECT
avg(price)
FROM most_expensive;
Functions
在 ClickHouse 中至少有兩種以上不同類型的函式,其中:
- Regular Functions (Functions):每一個 row 的資料都會獨立被處理,例如
lower(<column1>),即會對 column1 中每一個 row 套用lower這個函式 - Aggregate Function:將多個 rows 的資料累積成一個新的資料,例如
sum(<column1>) 則會根據所下的 query,最終算出多個 rows 的加總
# 檢視 ClickHouse 中所有的 functions
SELECT * FROM system.functions;
SHOW CREATE TABLE system.functions
/*
Row 1:
──────
statement: CREATE TABLE system.functions
(
`name` String,
`is_aggregate` UInt8,
`case_insensitive` UInt8,
`alias_to` String,
`create_query` String,
`origin` Enum8('System' = 0, 'SQLUserDefined' = 1, 'ExecutableUserDefined' = 2),
`description` String,
`syntax` String,
`arguments` String,
`returned_value` String,
`examples` String,
`categories` String
)
ENGINE = SystemFunctions
COMMENT 'Contains a list of all available ordinary and aggregate functions with their descriptions.'
*/
Regular Functions / Functions
Regular Functions @ SQL Reference > Functions
- string transform:
lower、upper、trim、normalize、encode
SEARCH
positionmultiFuzzMatchAnymultiSearchAllPositionsCaseInsensitive
SELECT DISTINCT
street,
# 每一個 street 檢查看看有沒有 abbey 或 road 的單字,有的話回傳其 position 否則回傳 0
# positions 會是一個 array,表示 'abbey' 或 'road' 所在的 position
multiSearchAllPositionsCaseInsensitive(
street,
['abbey', 'road']
) AS positions
FROM uk_price_paid
# positions 有其中一個為 0 就不要,表示要兩個單字同時存在
WHERE NOT has(positions, 0);
Dates and Times
now()toTimeZone(time, 'Asia/Taipei')toDate(time)toYYYYMM(time)toStartOfMonth(time)addWeeks(time, 2)formatDateTime(time, %Y/%m/%d)
WITH now() AS time
SELECT
toTimeZone(time, 'Asia/Taipei'),
toDate(time),
toYYYYMM(time),
time - 1,
time - INTERVAL 1 DAY,
toStartOfMonth(time),
addWeeks(time, 2),
formatDateTime(time, '%Y%m%d')
FORMAT VERTICAL;
/*
Row 1:
──────
toTimeZone(time, 'Asia/Taipei'): 2024-11-05 23:44:59
toDate(time): 2024-11-05
toYYYYMM(time): 202411
minus(time, 1): 2024-11-05 15:44:58
minus(time, toIntervalDay(1)): 2024-11-04 15:44:59
toStartOfMonth(time): 2024-11-01
addWeeks(time, 2): 2024-11-19 15:44:59
formatDateTime(time, '%Y%m%d'): 20241105
*/
搭配 WHERE 來過濾時間相當方便:
-- 找出 campaign_start_time 是 2024 年以後的資料
SELECT *
FROM events
WHERE campaign_start_time >= toDate('2024-01-01');
-- 找出 2024 年的資料
SELECT *
FROM events
WHERE toYear(campaign_start_time) = '2024';
-- 找出特定年月的資料
SELECT *
FROM events
WHERE toYYYYMM(campaign_start_time) = '202408';
-- 找出最近兩個年內的資料
SELECT *
FROM events
WHERE (campaign_start_time >= now() - toIntervalYear(2)) AND campaign_start_time < now();
-- 以月為單位,找出最近兩年內的資料
SELECT *
FROM events
WHERE month >= (toStartOfMonth(now()) - (INTERVAL 2 YEAR)) AND month < toStartOfMonth(now());
但需要找出某一時間區間的資料時,使用 toDate() 非常方便,例如, date >= toDate('2024-01-01') AND date <= toDate('2024-12-31')。
System
SELECT currentUser();
SELECT currentDatabase();
Aggregate Functions
Aggregation function @ SQL Reference > Functions
-
sum、max -
any -
argMax(street, price):找出 price 最高的 street -
quantiles(0.25, 0.5, ...)(age):取得 25th、50th percentile age 的值 -
uniqExact可以取得某個欄位最精確的「不重複值(unique)的數目」,如果只是需要近似值,則可以使用uniqSELECT uniqExact(COUNTRY_CODE) FROM pypi;uniq和DISTINCT的差別在於,uniq取得的是不重複值的「數目(count)」
-
topK(N)(column)- 計算
column中最常出現的前 N 筆,以 array 顯示 - 可以取代
COUNT+GROUP BY+ORDER BY的用法
- 計算
Combinators
Combinators @ ClickHouse > SQL Reference > Aggregate Functions
Combinator 是指任何 aggregate function 都可以加上這個後綴就會有作用,例如:
if:sumIf(column, condition)、countIf(condition)、avgIf(x, condition)、topKIf(N)(column, condition)topKIf(10)(street,street != ''):以 array 的方式顯示 street 不會空值的情況下,最常出現的前 10 筆資料
array:傳入的參數是 array,例如sumArray()、avgArray()map:傳入的參數是 map,例如sumMap()、avgMap()- ...
其他 Functions
splitByChar():可以把傳入的字串拆成 arrayconcat(column1, column2, column3)、concatWithSeparator(' ', column1, column2, column3)
Lambda Functions
arrayMap
在 arrayMap 這個函式中,可以帶入 lambda function:
WITH ['<b>hello</b>', '<i>world</i>'] AS my_html_array
SELECT arrayMap(s -> extractTextFromHTML(s), my_html_array)
FORMAT VERTICAL;
-- arrayMap(lambda(tuple(s), extractTextFromHTML(s)), my_html_array): ['hello','world']
SELECT arrayMap((x, y) -> least(x, y), [7, 102, 35], [9, 100, 25]);
-- arrayMap(lambda(tuple(x, y), least(x, y)), [7, 102, 35], [9, 100, 25]): [7,100,25]
User Defined Functions
CREATE FUNCTION mergePostcode AS (p1, p2) -> concat(p1, 2);
SELECT mergePostcode(postcode1, postcode2) FROM uk_price_paid;
其他
修改 ClickHouse Client Prompt 的方式
- 建立
custom-config.xml,並在裡面定義想要的 client prompt - 在連線的時候指定要套用的 config file
$ clickhouse client --config-file="custom-config.xml" -m
Performance Metric
檢查資料表使用的硬碟空間
keywords: disk space
SELECT
table,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
count() AS num_of_active_parts
FROM system.parts
WHERE (active = 1) AND (table LIKE '%<table_name>%')
GROUP BY table;
Statements
描述資料表
# 描述這個資料表中的欄位資訊
DESCRIBE my_table;
# 也可以 Describe 放在 s3 上的資料
DESCRIBE s3('https://learnclickhouse.s3.us-east-2.amazonaws.com/datasets/crypto_prices.parquet');
# 顯示這個 TABLE 在建立時所用的 SQL
SHOW CREATE TABLE my_table;
DDL (Data Definition Language)
keywords: CREATE, RENAME, TRUNCATE, DROP, ADD, DROP, CLEAR
針對 Table 的操作
# 顯示所有的 databases
SHOW DATABASES;
# 使用某個 database(預設使用 default)
use [database];
# 顯示目前 database 裡有哪些 tables(如果沒有寫 FROM xxx 則會是當前 "use" 的 database)
SHOW TABLES FROM SQL_EXAMPLES;
# 建立一個名為 "SQL_EXAMPLES" 的 database
CREATE DATABASE IF NOT EXISTS SQL_EXAMPLES;
# 在 SQL_EXAMPLES 這個 database 中,建立一個名為 "table1" 的 table
# 預設如果沒有指定 database,則會用正在 "use" 的 database
CREATE TABLE SQL_EXAMPLES.table1
(
Column1 String,
Column2 UInt16
)
ENGINE=Log;
# 在 SQL_EXAMPLES 這個 database 中,建立一個名為 "salary" 的 table
CREATE TABLE SQL_EXAMPLES.salary
(
salary Decimal(18, 2),
month Nullable(String),
name String
)
ENGINE=MergeTree
ORDER BY name;
# 檢視這個 table 的結構
SHOW CREATE TABLE SQL_EXAMPLES.salary;
# Rename a table
RENAME TABLE SQL_EXAMPLES.table1 TO SQL_EXAMPLES.table2
# 移除 table 中的所有 rows
TRUNCATE TABLE SQL_EXAMPLES.table2;
# 移除 table
DROP TABLE SQL_EXAMPLES.table2;
ALTER
Alter @ ClickHouse > Statements
針對 Column 的操作
keywords: ADD COLUMN, RENAME COLUMN, CLEAR COLUMN, DROP COLUMN
# ALTER TABLE [DB.][Table] ADD/RENAME/CLEAR/DROP COLUMN [Column] ...;
# 添加名為 "Column3" 的 Column,這個 Column 的資料型別會是 Nullable String
ALTER TABLE SQL_EXAMPLES.table2 ADD COLUMN Column3 Nullable(String);
# 將 Column3 改名成 Column4
ALTER TABLE SQL_EXAMPLES.table2 RENAME COLUMN Column3 TO Column4;
# 把 Column4 裡的資料清空
ALTER TABLE SQL_EXAMPLES.table2 CLEAR COLUMN Column4;
# 把 Column4 這個欄位砍掉
ALTER TABLE SQL_EXAMPLES.table2 DROP COLUMN Column4;
DQL (Data Query Language)
keywords: SELECT
# 如果沒有指定是那個 database 裡的 table,預設會去 query 正在 "use" 的 database
SELECT COUNT(name), is_aggregate FROM system.functions WHERE origin='System' GROUP BY is_aggregate ORDER BY is_aggregate DESC;
# 看某一個 Table 中總共有少筆資料
SELECT COUNT(1) FROM my_table;
DML (Data Manipulation Language)
keywords: INSERT, ALTER, UPDATE, DELETE
INSERT INTO
INSERT INTO Statement @ ClickHouse > Statements
# INSERT INTO [TABLE] [db.]table
# [(c1, c2, c3)] [SETTINGS ...]
# VALUES (v11, v12, v13), (v21, v22, v23), ...
# 新增兩個 row 的資料
INSERT INTO SQL_EXAMPLES.table1 VALUES ('a'), ('b');
# 新增一個 row 中三個 column 的資料
INSERT INTO SQL_EXAMPLES.table2 VALUES ('c', 'c', 'cat');
# 新增兩個 row 中兩個 column 的資料
INSERT INTO SQL_EXAMPLES.table2 (Column1, Column2) VALUES ('a', 'a'), ('b', 'b');
INSERT INTO SQL_EXAMPLES.salary VALUES (1200, 'Nov', 'a'), (1000, 'Jan', 'b'), (800, Null, 'd');
# 複製某個 table(pypi 的資料)到另一個 table(pypi2)
INSERT INTO pypi2 SELECT * FROM pypi;
# 把資料從 S3 上的 parquet 複製進到 pypi 這個 table
INSERT INTO pypi SELECT
TIMESTAMP,
COUNTRY_CODE,
URL,
PROJECT
FROM
s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2023/pypi_0_7_34.snappy.parquet');
ALTER TABLE (UPDATE & DELETE)
# UPDATE:把 Column2 為 'a' 的 value 改成 'apple'
ALTER TABLE SQL_EXAMPLES.table2 UPDATE Column2 = 'apple' WHERE Column2 = 'a';
# DELETE:把 Column 為 'apple' 的這個 row 刪除
ALTER TABLE SQL_EXAMPLES.table2 DELETE WHERE Column2 = 'apple';
# Lightweight Delete(只能用在 Engine 是 MergeTree family)
# https://clickhouse.com/docs/en/sql-reference/statements/delete
DELETE FROM SQL_EXAMPLES.table2 WHERE Column2 = 'b';
在 ClickHouse 中 Update 和 Delete 都被視為是 mutation operation,而 mutation operation 都會需要消耗許多的資源。
JOIN
原本的兩張 table 長這樣:
SELECT * FROM SQL_EXAMPLES.employee;
# ┌─name─┬─city──┐
# 1. │ a │ city1 │
# 2. │ b │ ᴺᵁᴸᴸ │
# 3. │ c │ city3 │
# └──────┴───────┘
SELECT * FROM SQL_EXAMPLES.salary;
# ┌─salary─┬─month─┬─name─┐
# 1. │ 222 │ Nov │ a │
# 2. │ 1000 │ Jan │ b │
# 3. │ 800 │ ᴺᵁᴸᴸ │ d │
# └────────┴───────┴──────┘
# ┌─salary─┬─month─┬─name─┐
# 4. │ 777 │ Nov │ z │
# └────────┴───────┴──────┘
基本的語法長這樣:
# SELECT [columns]
# FROM [LEFT TABLE]
# [JOIN TYPE] [RIGHT TABLE]
# ON [EXPRESS LIST]
Inner Join(都 mapping 到的才有)
# INNER JOIN(都 mapping 到的才有)
SELECT
employee.name,
employee.city,
salary.salary,
salary.month,
salary.name
FROM SQL_EXAMPLES.employee AS employee
INNER JOIN SQL_EXAMPLES.salary AS salary ON employee.name = salary.name;
# ┌─name─┬─city──┬─salary─┬─month─┬─salary.name─┐
# 1. │ a │ city1 │ 222 │ Nov │ a │
# 2. │ b │ ᴺᵁᴸᴸ │ 1000 │ Jan │ b │
# └──────┴───────┴────────┴───────┴─────────────┘
Left Join
以左邊(前面)的 table 為主:
SELECT
employee.name,
employee.city,
salary.salary,
salary.month,
salary.name
FROM SQL_EXAMPLES.employee AS employee
LEFT JOIN SQL_EXAMPLES.salary AS salary ON employee.name = salary.name;
# ┌─name─┬─city──┬─salary─┬─month─┬─salary.name─┐
# 1. │ a │ city1 │ 222 │ Nov │ a │
# 2. │ b │ ᴺᵁᴸᴸ │ 1000 │ Jan │ b │
# 3. │ c │ city3 │ 0 │ ᴺᵁᴸᴸ │ │
# └──────┴───────┴────────┴───────┴─────────────┘
Right Join
以右邊(後面)的 table 為主:
SELECT
employee.name,
employee.city,
salary.salary,
salary.month,
salary.name
FROM SQL_EXAMPLES.employee AS employee
RIGHT JOIN SQL_EXAMPLES.salary AS salary ON employee.name = salary.name;
# ┌─name─┬─city──┬─salary─┬─month─┬─salary.name─┐
# 1. │ a │ city1 │ 222 │ Nov │ a │
# 2. │ b │ ᴺᵁᴸᴸ │ 1000 │ Jan │ b │
# └──────┴───────┴────────┴───────┴─────────────┘
# ┌─name─┬─city─┬─salary─┬─month─┬─salary.name─┐
# 3. │ │ ᴺᵁᴸᴸ │ 800 │ ᴺᵁᴸᴸ │ d │
# 4. │ │ ᴺᵁᴸᴸ │ 777 │ Nov │ z │
# └──────┴──────┴────────┴───────┴─────────────┘
Outer Join(FULL OUTER JOIN)
取兩個 Table 的
SELECT
employee.name,
employee.city,
salary.salary,
salary.month,
salary.name
FROM SQL_EXAMPLES.employee AS employee
FULL OUTER JOIN SQL_EXAMPLES.salary AS salary ON employee.name = salary.name;
# ┌─name─┬─city──┬─salary─┬─month─┬─salary.name─┐
# 1. │ a │ city1 │ 222 │ Nov │ a │
# 2. │ b │ ᴺᵁ�ᴸᴸ │ 1000 │ Jan │ b │
# 3. │ c │ city3 │ 0 │ ᴺᵁᴸᴸ │ │
# └──────┴───────┴────────┴───────┴─────────────┘
# ┌─name─┬─city─┬─salary─┬─month─┬─salary.name─┐
# 4. │ │ ᴺᵁᴸᴸ │ 800 │ ᴺᵁᴸᴸ │ d │
# 5. │ │ ᴺᵁᴸᴸ │ 777 │ Nov │ z │
# └──────┴──────┴────────┴───────┴─────────────┘
UNION
SELECT name
FROM SQL_EXAMPLES.employee
UNION ALL
SELECT name
FROM SQL_EXAMPLES.salary;
# ┌─name─┐
# 1. │ a │
# 2. │ b │
# 3. │ d │
# └──────┘
# ┌─name─┐
# 4. │ z │
# └──────┘
# ┌─name─┐
# 5. │ a │
# 6. │ b │
# 7. │ c │
# └──────┘
如果只要顯示 DISTINCT 的 name,需要使用 SELECT DISTINCT [COLUMN]:
SELECT DISTINCT name
FROM
(
SELECT name
FROM SQL_EXAMPLES.employee
UNION ALL
SELECT name
FROM SQL_EXAMPLES.salary
)
# ┌─name─┐
# 1. │ z │
# └──────┘
# ┌─name─┐
# 2. │ a │
# 3. │ b │
# 4. │ c │
# └──────┘
# ┌─name─┐
# 5. │ d │
# └──────┘
Integration(整合外部資料)
描述資料表
# 描述 s3 上 parquet 的資料
# 當使用 describe_compact_output = 1 時,DESCRIBE 只會回傳欄位名稱和其資料型別,不會回傳額外的資訊
# 這個設定適合用在,當資料表中有多個欄位、或者只想簡單看一下資料表結構
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
SETTINGS describe_compact_output = 1;
複製資料表(schema)
- With a Schema and Data Cloned from Another Table @ Statement > Create > Table
- 使用
CREATE TABLE AS SELECT來複製一份給 ClickHouse 使用的資料表:- 最好一開始就把 PRIMARY KEY 指定好,因為 ClickHouse 沒辦法直接修改 Primary Key,而是得要建立新的 Table
# Example 1
CREATE TABLE new_table ENGINE = MergeTree PRIMARY KEY (COLUMN_1) AS origin_table;
# Example 2
CREATE TABLE posts
ENGINE = MergeTree
PRIMARY KEY (COLUMN_1)
EMPTY AS
SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet');
- 使用
SHOW CREATE TABLE <table>檢視建立出的資料表:
SHOW CREATE TABLE posts;
- 需要的話可以修改欄位的 data type 等等:
ALTER TABLE table_name MODIFY COLUMN column_name LowCardinality(String);
複製資料
# Example 1
INSERT INTO new_table SELECT * FROM origin_table;
# Example 2
# 把資料從 S3 上的 parquet 複製進到 pypi 這個 table
INSERT INTO pypi SELECT
TIMESTAMP,
COUNTRY_CODE,
URL,
PROJECT
FROM
s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2023/pypi_0_7_34.snappy.parquet');
安裝與啟動
使用 Docker Compose
請參考這個 clickhouse-docker-compose 這個 repository。
使用 Homebrew 安裝
$ brew install --cask clickhouse
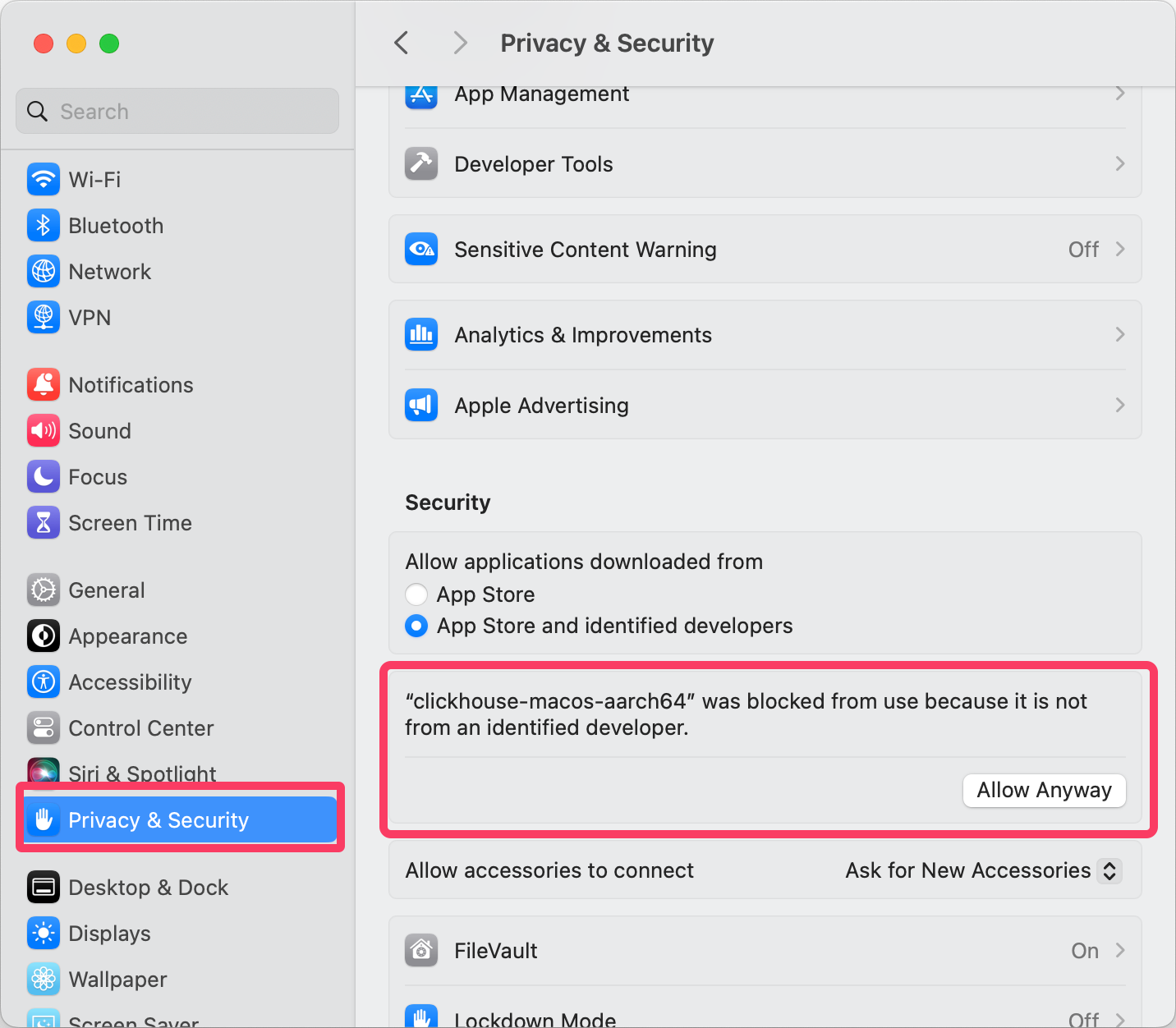
使用 Homebrew 安裝時,會需要到 Privacy & Security 中去允許安裝:
接著,建議開一個給 ClickHouse Database 用的資料夾,例如 clickhouse-db:
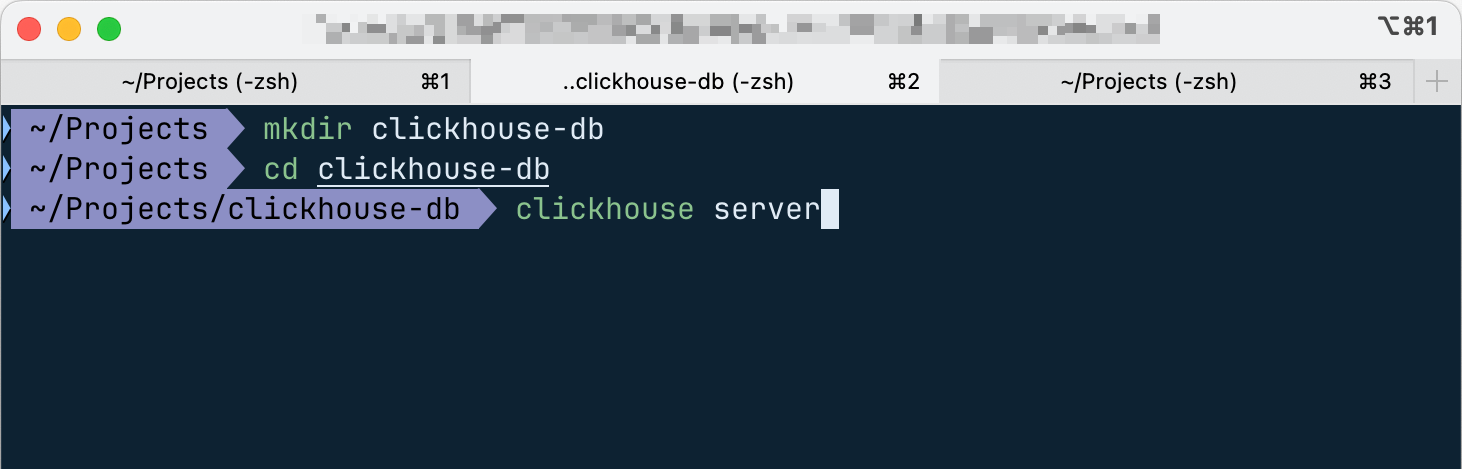
進到該資料後,輸入 clickhouse server 即可啟動 clickhouse 的 server,啟動後,該資料夾即會建立出許多和 ClickHouse database 有關的檔案:
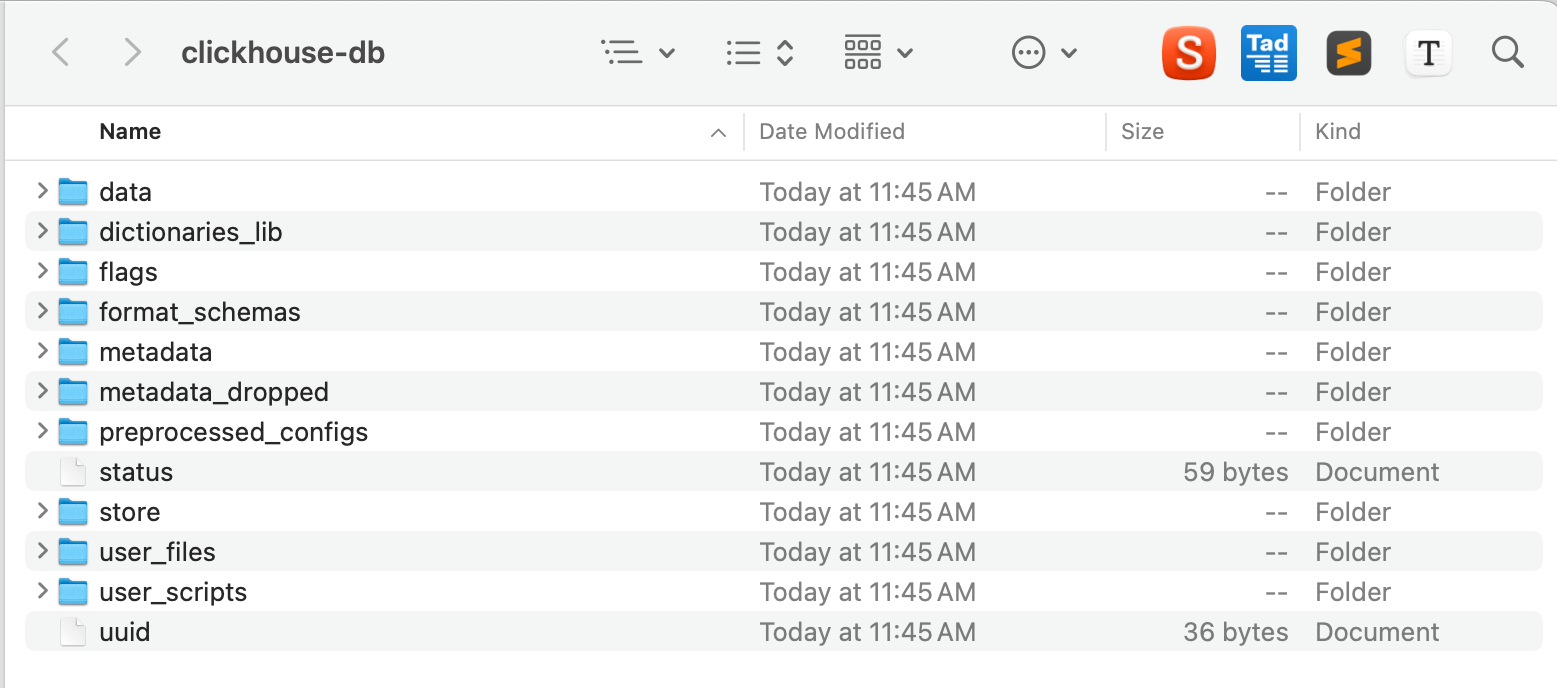
當執行 clickhouse server 時,clickhouse 資料庫相關的檔案會在該路徑被建立出來,因此會建議開一個資料夾,然後在這個資料夾中執行 clickhouse server 的指令,如此可以避免資料庫相關的檔案散落在其他地方。
$ clickhouse server # 等價於文件中的 "./clickhouse server" 或 "clickhouse-server",--daemon 可以讓 clickhouse server 在背景執行
$ clickhouse client # 等價於文件中的 "./clickhouse client" 或 "clickhouse-client"
$ clickhouse # 等價於文件中的 "./clickhouse",會啟動 clickhouse-local
clickhouse-local讓你能在不需要設定檔的情況下,使用 ClickHouse SQL 處理 local 和 remote 的檔案。這裡資料只會暫存,一點重新啟動 clickhouse-local,與那邊建立的 table 就會消失。
ClickHouse server 預設會執行在 TCP Port 9000。Web UI 則會執行在 HTTP 8123。
除了使用 clickhouse client 連進 ClickHouse sever 外,ClickHouse 本身有提供一個 Web UI,在啟動 server 後可以進到 http://localhost:8123/play,就可以在這裡下 ClickHouse 的 SQL。