[Golang] Concurrency Patterns
參考資料
基本觀念
讓別人不會知道底層是以 Concurrency 運作
Concurrency 算是實作細節(implementation detail),而好的 API 設計應該要盡可能隱藏使用者不需要知道的這些實作細節。也就是說,實務上在設計 API 時,不論是 API 的型別、函式或方法,你都不應該將 channel 或 mutex 暴露給使用者存取。除非,你的 API 有設計要提供 concurrency 的 helper function,這種情況下可以是個例外。
每當啟動一個 goroutine,都必須要確保這個 goroutine 會結束
和變數不同,go runtime 沒辦法偵測到 goroutine 未來是否有可能會再次被使用到,因此如果 goroutine 未能正確退出(例如一直阻塞或等待),它所佔用的資源(如堆疊空間和執行資源)將無法被釋放,導致資源洩漏。這種現象被稱為 goroutine leak。
為了避免 goroutine leak,我們要確保 goroutine 有被退出。具體來說,常見的是搭配 context 或另一個 channel 來做 cancel 的操作。
舉例來說,下面 countTo 函式裡的 goroutine,原本預期應該要把所有的數字塞進 ch 中,但因為 main 提早被結束,沒有地方繼續讀取 ch 裡的資料,使得 countTo 裡的 go routine 就會卡在那裡,造成 goroutine 沒辦法正確退出,進入導致 goroutine leak:
package main
import "fmt"
func countTo(max int) <-chan int {
ch := make(chan int)
go func() {
for i := 0; i < max; i++ {
ch <- i
}
close(ch)
}()
return ch
}
func main() {
for i := range countTo(10) {
// 在這個例子中,因為沒有把所有會傳入 ch 的資料都讀完就提早 break
// 這會導致 countTo 裡面的 goroutine 一直卡在那裡,等其他 goroutine 來把 channel 中的資料讀出來,
// 但因為程式中沒有其他地方會讀取這個 channel 的資料,進而導致這些 goroutine 沒辦法被正確退出,
// 所以它就會造成 goroutine leak
if i > 5 {
break
}
fmt.Println(i)
}
fmt.Println("Done")
}
要解決這個問題,context 是其中一種做法:
簡單或資料量小的操作,使用 concurrent feature 可能更慢
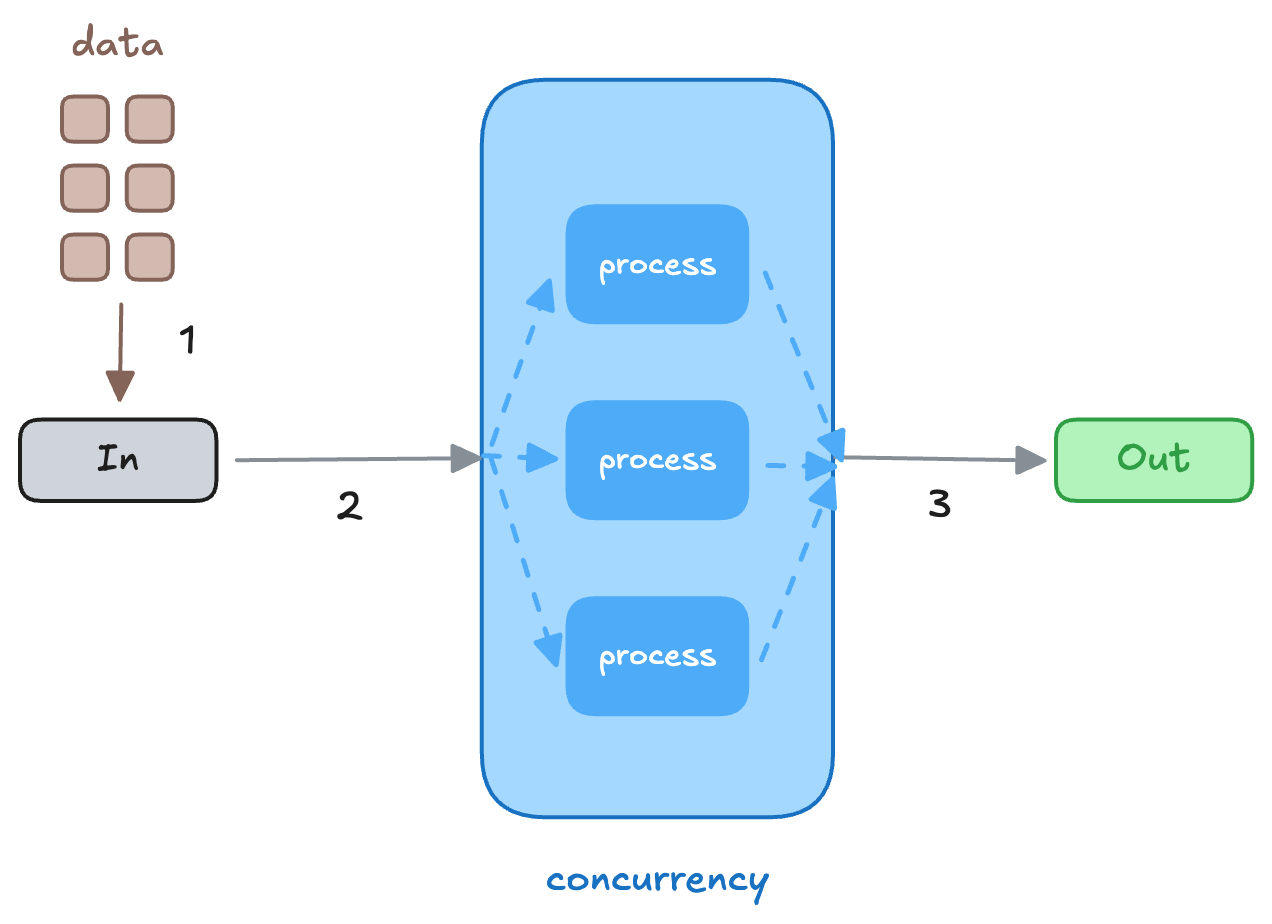
底下是範例程式碼,它的邏輯是:
- 把所有資料寫進
inchannel - data pipeline:建立三個 go routine
- 把資料從
in拿出來 - 處理完後
- 把資料放到
out
- 把資料從
- 把資料從
outchannel 拿出來
這裡之所以要建立 in 和 out 來個 channel 是因為透過這個方式,才能在 go routine 中拿到資料。
package main
import (
"fmt"
"sync"
)
const numGoRoutines = 5
func processData(val int) int {
//time.Sleep(time.Millisecond * 50)
return val * 2
}
func dataPipeline(datafeed []int) []int {
// 透過 WaitGroup 來確保 out channel 也會被關閉
var wg sync.WaitGroup
wg.Add(numGoRoutines)
in := make(chan int, numGoRoutines)
out := make(chan int, numGoRoutines)
// 建立一個 goroutine 將資料放入 in channel
go func() {
for _, v := range datafeed {
in <- v
}
close(in)
}()
// Concurrency 處理資料的地方
// 建立五個不同的 goroutine 用來「同時處理資料」
// 每個 goroutine 會將 in channel 的資料取出,並將處理後的資料放入 out channel
for i := 0; i < numGoRoutines; i++ {
go func() {
for v := range in {
out <- processData(v)
}
wg.Done()
}()
}
// 從 out channel 取出資料
outVals := make([]int, 0, len(datafeed))
for i := 0; i < len(datafeed); i++ {
outVals = append(outVals, <-out)
}
wg.Wait()
close(out)
return outVals
}
func main() {
datafeed := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
out := dataPipeline(datafeed)
fmt.Println(out)
}
跑 Benchmark:
$ go test -bench=.
package main
import "testing"
func BenchmarkDataPipeline(b *testing.B) {
data := make([]int, 1000)
for i := 0; i < 1000; i++ {
data[i] = i + 1
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
dataPipeline(data)
}
}
func BenchmarkDataPipelineSync(b *testing.B) {
data := make([]int, 1000)
for i := 0; i < 1000; i++ {
data[i] = i + 1
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
dataPipelineSync(data)
}
}
會得到類似的結果:
BenchmarkDataPipeline在時限內一共被執行了4819次,每次操作需要耗時約240376nanosecondsBenchmarkDataPipelineSync在時限內一共被執行了1000000次,每次操作需要耗時約1150nanoseconds- 說明了使用 Sync 的方法會比用 concurrency 的方法來的快
goos: darwin
goarch: arm64
pkg: go-playground/concurrency/basic
BenchmarkDataPipeline-8 4819 240376 ns/op
BenchmarkDataPipelineSync-8 1000000 1150 ns/op
PASS
ok go-playground/concurrency/basic 3.068s
但是如果在上面 process 函式中,如果我們加上 time.Sleep(10 * time.Millisecond),結果就會不同:
BenchmarkDataPipeline在時限內一共被執行了1次,每次操作需要耗時約2190608416nanosecondsBenchmarkDataPipelineSync在時限內一共被執行了1次,每次操作需要耗時約10926351042nanoseconds- 可以看到,當需要處理複雜運算或 io 操作時,使用 concurrency 的方法會比較快,而且當任務約困難(
time.Sleep的時間越久),這樣的情況約明顯
goos: darwin
goarch: arm64
pkg: go-playground/concurrency/basic
BenchmarkDataPipeline-8 1 2190608416 ns/op
BenchmarkDataPipelineSync-8 1 10926351042 ns/op
PASS
ok go-playground/concurrency/basic 13.348s