[note] Kafka
資料來源
TL;DR
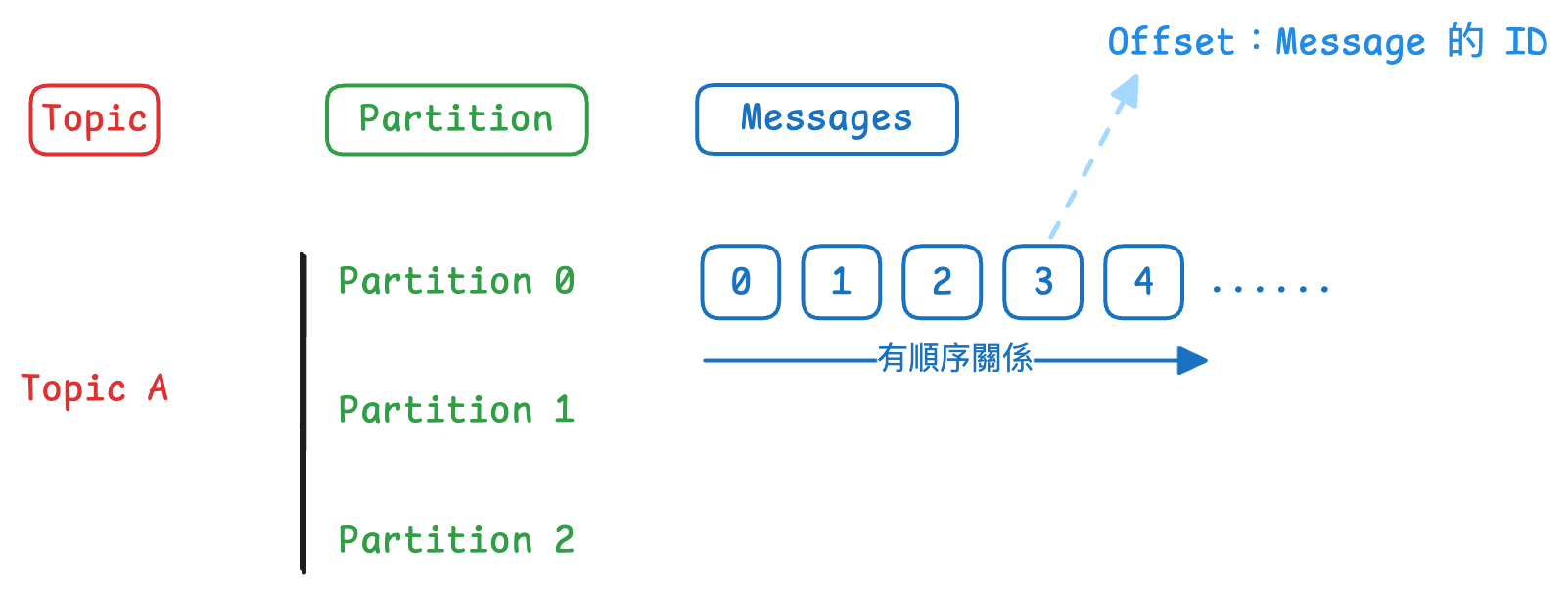
- Kafka Topic 由許多的
Partition組成;Partition 中則有許多的Messages,每個 Messages 有自己的 ID,稱作Offset。
Kafka Theory
Kafka Topic
- Kafka Topic 就類似資料庫中 Table 的概念,但是它沒有任何型別和欄位的限制,支援任何形式的 message format
- 需要透過 Kafka Producers 來寫入資料,並透過 Kafka Consumers 來讀取資料
- Kafka Topics 內的資料是不可變的(immutable),一旦資料寫進 Partition 後,你不能更新或刪除 Kafka 內的資料,你只能一直將資料寫進 Partition
- Kafka 內的資料只會保存一段時間(預設是一週)
資訊
一連串的 messages 就稱作 data stream。
提示
Kafka Topic 由許多的 Partition 組成;Partition 中則有許多的 Messages,每個 Messages 有自己的 ID,稱作 Offset。
Partitions and offsets
-
Partitions:一個 Topic 可以被切分成多個
Partitions- 如果沒有特別指定 partition 的話,資料會被隨機寫入到不同的 partition
-
Offset:單個 Partition 內,每個 message 被 assign 的 ID
- Partitions 中的每一個 message 都會有一個 incremental ID,這個 ID 就稱作
offset - 每一個 Partition 中的 offset 是有順序關係的,但跨 Partition 間 offset 則沒有順序關係
- Partitions 中的每一個 message 都會有一個 incremental ID,這個 ID 就稱作
Kafka Producers
- Producers 會知道要把資料寫進那一個 Topic 中的那一個 Partition
- Producers 會建立 Message
- 如果 Kafka broker 故障,Producer 能夠自動復原(recover)
- Producer 在傳送資料的時候,可以幫 Message 帶上
Key- 如果沒個 Key(
key = null),則資料會以 round robin 的方式寫入不同 partition - 如果有給 Key,則相同 key 的資料會被寫到同一個 partition
- 如果沒個 Key(
提示
如果需要確認 message 的順序性,就需要給 key,通常會欄位中的某個 ID 當作 key。例如,如果希望確保某個使用者收到 message 的順序,就可以用 user_id 當作 key。
Kafka Message
Kafka Message 是透過 Kafka Producer 產生,並包含下來元素:
- Key: binary (nullable)
- Value: binary (nullable)
- Compression Type: none, gzip, snappy, etc
- Headers: Key-value paired (optional)
- Partition + Offset
- Timestamp
Message Serializer
Kafka 只接受 bytes,所以 producer 產生的 messages 會是 byte,consumer 接受的 messages 也是 bytes。但當我們從 consumer 拿資料出來時,並不會是 Byte。
- message serialization:將資料(物件)轉成 byte
Kafka Popular Use Cases
Top Kafka Use Cases You Should Know @ bytebytego
- Log Analysis
- Kafka 可以同時接受來自多個微服務的日誌
- 常搭配整合 Elasticsearch、Logstash、Kibana(ELK)
- Logstash 從 Kafka 拉資料、然後把資料傳進 Elasticsearch,最後透過 Kibana 來分析和視覺化這些 real-time log
- Real-time Machine Learning Pipelines
- 常搭配整合 Apache Flink、Apache Spark
- Real-time System Monitoring and Alerting
- Change Data Capture (CDC)
- CDC 是一種方法,追蹤並擷取 source database 的資料變更,並且即時的複製這個變更到其他的系統中
- 做法上會把 source database 的 transaction log 傳到 kafka 中,接著透過 Kafka connect 的架構(例如 ElasticSearch Connector、Redis Connector、Database Connector)來將資料同步到下游(例如,elastic search、redis 或 database)
- System Migration
- 利用 Kafka 可以 replay message 的特性,維持資料的一致性
- Kafka 不只在 system migration 的過程中可以幫助資料轉換,還可以作為新舊系統的緩衝